연구
최신연구
View
| [한욱신 교수] 데이터베이스 재생 시스템을 위한 고속 의존성 그래프 생성 방법 개발 | ||
|---|---|---|
| 작성자 시스템 | 작성일 24/02/05 (00:00) | 조회수 949 |
[연구의 필요성]
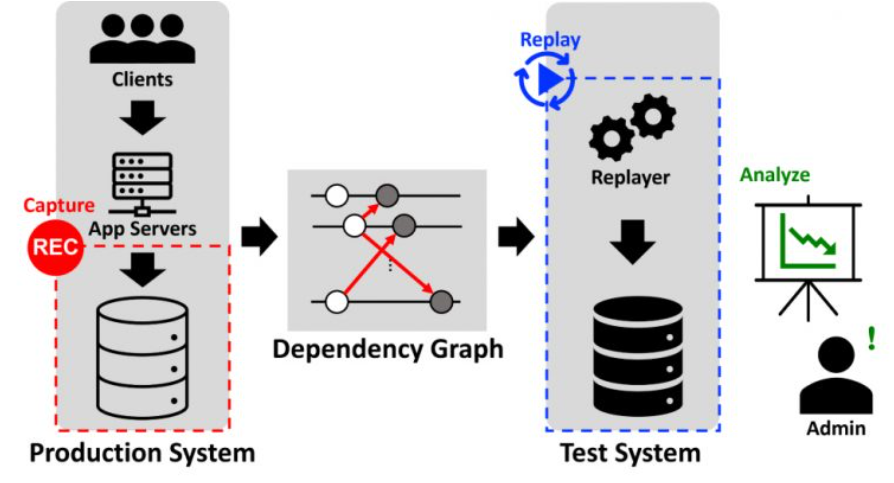
데이터베이스 재생 시스템은 프로덕션 환경에서 데이터베이스 워크로드를 수집하고 테스트 환경에서 재생해, 소프트웨어 및 하드웨어 변경에 따른 성능 변화와 버그를 프로덕션 시스템에 영향 없이 검사한다. 데이터베이스 재생 시스템은 워크로드 내 각 요청(request)의 재생이 수집 시와 동일한 결과를 내도록 보장하기 위해 의존성 그래프(dependency graph)를 생성하는데, 이 그래프는 각 요청을 정점으로, 의존성이 있는 두 요청 간의 선후 관계를 간선으로 나타낸다. 그러나 기존의 방법은 각 요청마다 다른 요청들을 탐색하여 간선들을 생성하는데, 최악의 경우 워크로드 내 요청 수의 제곱에 비례하는 시간을 소모하여, 워크로드 수집에서 재생으로 이어지는 전체 과정에서 병목을 유발한다. 또한, 이렇게 생성되는 간선의 대다수는 중복 간선(redundant edge; 제거하더라도 다른 경로에 의해 선후 관계가 지켜지는 간선)이기 때문에, 워크로드 재생 전 이들을 제거하는 값비싼 전이적 축소(transitive reduction) 과정의 비용을 증가시킨다. 따라서 시간에 따라 변화하는 워크로드를 지속적으로 수집하고 신속하게 재생하여 테스트하기 위해서는, 중복 간선이 적은 간결한 의존성 그래프를 효율적으로 생성할 필요가 있다.
데이터베이스 재생 시스템은 프로덕션 환경에서 데이터베이스 워크로드를 수집하고 테스트 환경에서 재생해, 소프트웨어 및 하드웨어 변경에 따른 성능 변화와 버그를 프로덕션 시스템에 영향 없이 검사한다. 데이터베이스 재생 시스템은 워크로드 내 각 요청(request)의 재생이 수집 시와 동일한 결과를 내도록 보장하기 위해 의존성 그래프(dependency graph)를 생성하는데, 이 그래프는 각 요청을 정점으로, 의존성이 있는 두 요청 간의 선후 관계를 간선으로 나타낸다. 그러나 기존의 방법은 각 요청마다 다른 요청들을 탐색하여 간선들을 생성하는데, 최악의 경우 워크로드 내 요청 수의 제곱에 비례하는 시간을 소모하여, 워크로드 수집에서 재생으로 이어지는 전체 과정에서 병목을 유발한다. 또한, 이렇게 생성되는 간선의 대다수는 중복 간선(redundant edge; 제거하더라도 다른 경로에 의해 선후 관계가 지켜지는 간선)이기 때문에, 워크로드 재생 전 이들을 제거하는 값비싼 전이적 축소(transitive reduction) 과정의 비용을 증가시킨다. 따라서 시간에 따라 변화하는 워크로드를 지속적으로 수집하고 신속하게 재생하여 테스트하기 위해서는, 중복 간선이 적은 간결한 의존성 그래프를 효율적으로 생성할 필요가 있다.
[포스텍이 가진 고유의 기술]
본 기술은 단일 스캔과 메모이제이션(memoization)을 활용하여 간선을 생성하는 데 필요한 최소한의 정보만 메모 자료구조에 유지하고 이로부터 간결한 의존성 그래프를 효율적으로 생성한다. 먼저, 중복된 간선의 대부분을 차지하는 두 가지 중복 유형을 정의하고 분석하여, 이러한 중복을 갖지 않는 간선을 생성하는 데 필요한 최소한의 정보만을 메모 자료구조에 유지한다. 또한, 각 요청마다 다른 요청을 탐색하는 대신 단일 스캔으로 메모 자료구조로부터 간선을 생성하는 효율적인 알고리즘을 제안하여, 요청 수에 비례하는 시간 안에 간결한 의존성 그래프를 생성한다.
본 기술은 단일 스캔과 메모이제이션(memoization)을 활용하여 간선을 생성하는 데 필요한 최소한의 정보만 메모 자료구조에 유지하고 이로부터 간결한 의존성 그래프를 효율적으로 생성한다. 먼저, 중복된 간선의 대부분을 차지하는 두 가지 중복 유형을 정의하고 분석하여, 이러한 중복을 갖지 않는 간선을 생성하는 데 필요한 최소한의 정보만을 메모 자료구조에 유지한다. 또한, 각 요청마다 다른 요청을 탐색하는 대신 단일 스캔으로 메모 자료구조로부터 간선을 생성하는 효율적인 알고리즘을 제안하여, 요청 수에 비례하는 시간 안에 간결한 의존성 그래프를 생성한다.
[연구의 의미]
본 연구는 데이터베이스 재생 시스템의 의존성 그래프 생성 과정을 최대 100배 이상 가속하여, 수집에서 재생으로 이어지는 전체 과정에서의 병목을 제거하고 신속한 재생 결과 확인이 가능하도록 하였다.
본 연구는 데이터베이스 재생 시스템의 의존성 그래프 생성 과정을 최대 100배 이상 가속하여, 수집에서 재생으로 이어지는 전체 과정에서의 병목을 제거하고 신속한 재생 결과 확인이 가능하도록 하였다.
[연구결과의 진행 상태 및 향후 계획]
본 연구는 데이터베이스 시스템 분야 최고 학술대회인 ACM SIGMOD 2024에 발표될 예정이다. 향후 데이터베이스 재생 단계에서의 동시성 향상 방법을 연구하여, 초당 백만 단위의 트랜잭션을 초고속으로 처리하는 현대 학술용 데이터베이스 시스템에서도 데이터베이스 재생을 지원하고자 한다.
본 연구는 데이터베이스 시스템 분야 최고 학술대회인 ACM SIGMOD 2024에 발표될 예정이다. 향후 데이터베이스 재생 단계에서의 동시성 향상 방법을 연구하여, 초당 백만 단위의 트랜잭션을 초고속으로 처리하는 현대 학술용 데이터베이스 시스템에서도 데이터베이스 재생을 지원하고자 한다.
[성과와 관련된 실적]
1. Lee, W., Ha, J., Han, W.-S., Park, C., Park, M., Han, J., and Lee, J. “DoppelGanger++: Towards Fast Dependency Graph Generation for Database Replay.” Proceedings of the ACM on Management of Data 2.1 (2024), pp. 67:1–67:26. (Corresponding author)
1. Lee, W., Ha, J., Han, W.-S., Park, C., Park, M., Han, J., and Lee, J. “DoppelGanger++: Towards Fast Dependency Graph Generation for Database Replay.” Proceedings of the ACM on Management of Data 2.1 (2024), pp. 67:1–67:26. (Corresponding author)
[성과와 관련된 이미지]