연구
최신연구
View
| [이근배 교수] Cross-lingual Back-Parsing: Utterance Synthesis from Meaning Representation for Zero-Resource Semantic Parsing | ||
|---|---|---|
| 작성자 시스템 | 작성일 24/10/25 (00:00) | 조회수 904 |
[연구의 필요성]
Semantic Parsing(SP)은 자연어로 표현된 utterance를 SQL이나 파이썬 코드와 같은 의미 표현으로 변환하는 기술이다. 이러한 작업을 학습시키기 위한 영어 데이터는 풍부하게 확보되어 있지만, 다국어 데이터셋은 상대적으로 부족하여 최근에는 다국어 pretrained language model을 활용한 zero-shot cross-lingual transfer 기법으로 SP 모델을 다국어로 확장하려는 노력이 이루어지고 있다. 그럼에도 불구하고 영어와 비영어 언어 간의 성능 차이는 여전히 상당하다.
[포스텍이 가진 고유의 기술]
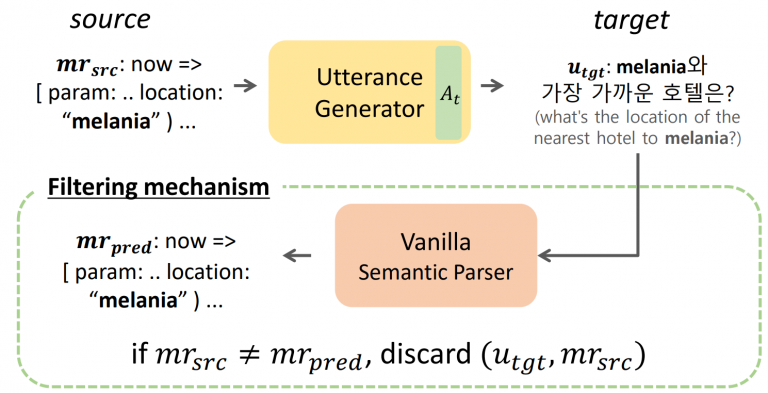
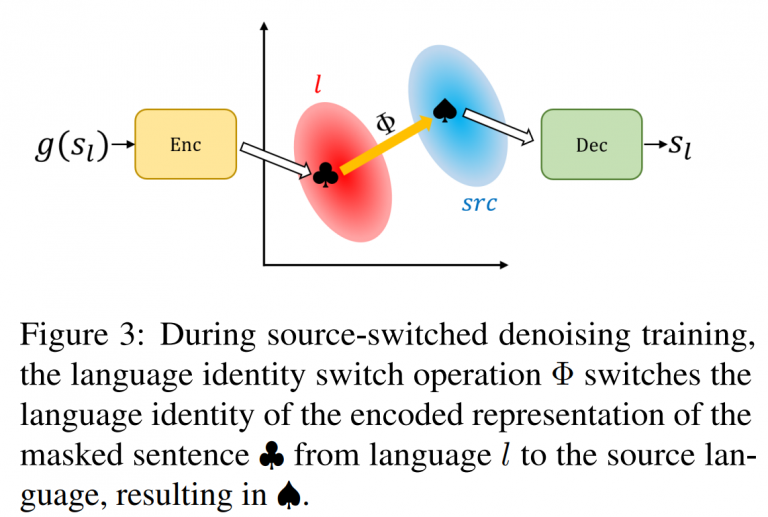
본 연구에서는 Cross-lingual Back Parsing(CBP)이라는 기술을 제안한다. 이 기술은 다국어 번역기나 병렬 코퍼스의 존재를 가정하지 않는 zero-resource 환경에서 작동한다. CBP는 다국어 pretrained language model의 인코더 표현 공간의 기하학적 특성을 활용하여 주어진 의미 표현(meaning representation)으로부터 다양한 언어의 utterance를 합성할 수 있다. 실험 결과, CBP는 도전적인 zero-resource 상황에서도 목표 언어로의 utterance 합성을 성공적으로 수행했을 뿐만 아니라, 그 의미 또한 효과적으로 보존함을 확인할 수 있었다. 또한, CBP로 합성된 다국어 데이터를 기존의 영어 데이터와 함께 사용하면 SP 모델의 다국어 성능이 크게 향상되는 것을 확인할 수 있었다.
[연구의 의미]
본 연구는 기존에 다루어지지 않았던 zero-resource 환경에서의 다국어 semantic parsing 문제를 해결하고자 하였으며, multilingual pretrained language model의 인코더 표현 공간을 조작한 학습 방법을 통해 모델의 생성 언어를 통제할 수 있음을 밝혀냈다. 이 방법론은 semantic parsing뿐만 아니라 다양한 seq2seq 작업에서도 다국어 성능을 향상시키는 데 활용될 수 있을 것이다.
[연구결과의 진행 상태 및 향후 계획]
본 연구는 자연어처리 분야 최우수 국제학술대회인 EMNLP2024에 소개될 예정이다. 추후에는 code와 같은 복잡한 meaning representation을 대상으로 해당 방법론을 확장할 방법을 모색하려고 한다.
[성과와 관련된 실적]
Deokhyung Kang, Seonjeong Hwang, Yunsu Kim, Gary Geunbae Lee, EMNLP 2024 (accepted)
[성과와 관련된 이미지]