연구
최신연구
View
| [이남훈 교수] SASSHA: Sharpness-aware Adaptive Second-order Optimization with Stable Hessian Approximation | ||
|---|---|---|
| 작성자 시스템 | 작성일 25/07/04 (11:43) | 조회수 1117 |
[연구의 필요성]
모델의 규모가 커질수록 성능이 향상된다는 연구들이 다수 보고되면서, 최근에는 ChatGPT, Gemini 와 같은 대규모 모델이 활발히 활용되고 있다. 그러나 이러한 모델의 학습에는 방대한 데이터셋과 거대한 모델 크기 때문에 막대한 시간이 소요되며, 모델 파라미터를 수백만 번 이상 업데이트해야 하는 경우도 많다. 예를 들어, GPT-4는 1만 개 이상의 A100GPU를 사용해 약 4개월간 학습되었으며, 이 과정에서 약 1억 달러가 넘는 비용이 투입된 것으로 알려져 있다.
이러한 배경에서 모델 학습 속도를 높이는 것은 대규모 모델의 확장을 가능하게 하고, 학습 비용 절감의 핵심 과제로 부상하고 있다. 최근에는 이를 해결하기 위한 방안으로, 2차 미분 정보를 근사적으로 활용하는 근사 2차 최적화 방법 (approximate second-order optimization)이 주목받고 있다. 하지만 역설적으로, 이러한 기법들은 학습의 궁극적 목표인 새로운 데이터에 대한 일반화 성능에서 기존의 1차 최적화 방법보다 떨어진다는 경향이 여러 연구를 통해 보고된 바 있다. 이는 근사 2차 최적화 방식의 실질적인 활용 가능성에 대한 근본적인 의문을 제기했다.
본 연구에서는 이러한 한계를 극복하고자, 일반화 성능을 효과적으로 개선함과 동시에 계산 효율성까지 확보할 수 있는 새로운 근사 2차 최적화 알고리즘을 제안한다. 이 알고리즘은 기존 기법의 실용적 약점을 보완하여, 대규모 모델의 학습을 보다 빠르게 수행할 수 있는 가능성을 제시한다.
[포스텍이 가진 고유의 기술]
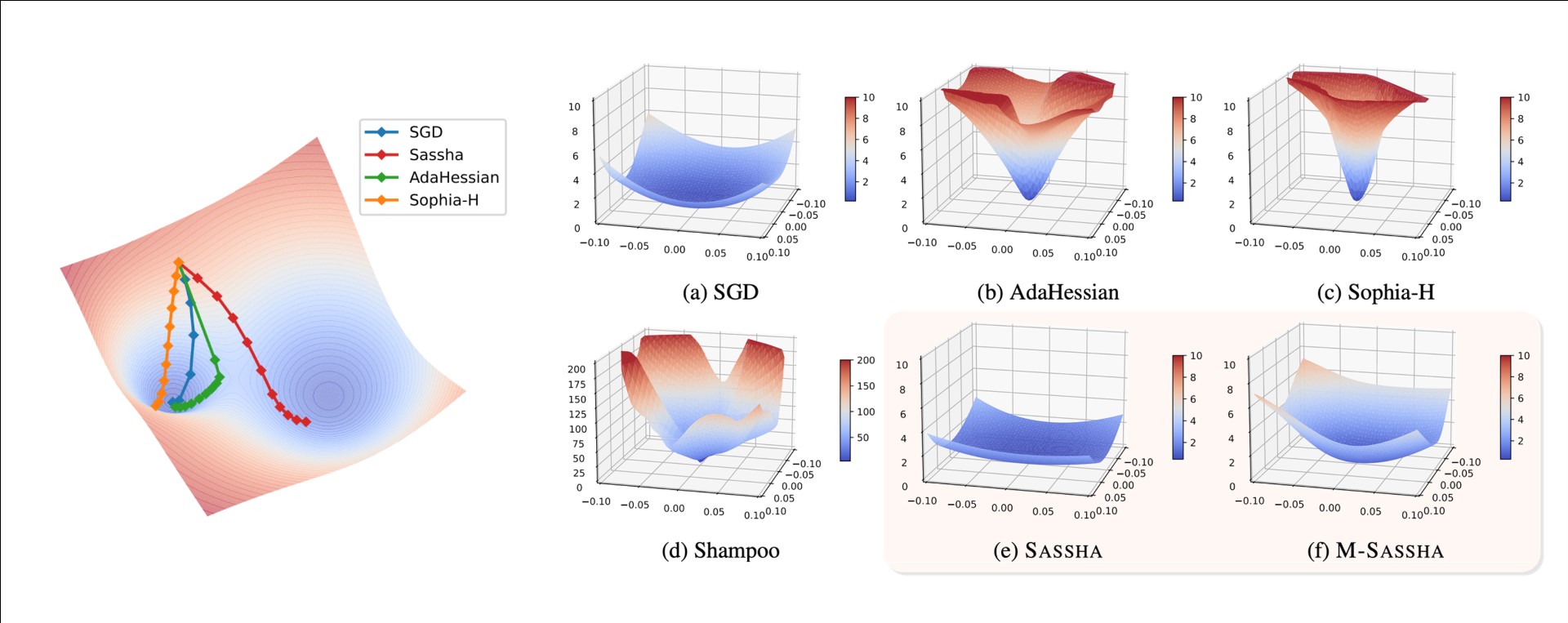
본 연구에서는 근사 2차 최적화 기법이 낮은 일반화 성능을 보이는 원인을 손실 함수의 지형적 구조(loss landscape) 관점에서 분석하였다. 실험적 및 이론적 분석을 통해, 근사 2차 최적화 기법이 찾아내는 해(solution)는 지나치게 곡률이 큰(sharp) 지점에 위치하는 경향이 있으며, 이것이 일반화 성능 저하의 핵심 원인 중 하나일 수 있음을 확인하였다.
이 문제를 해결하고자 우리는 곡률이 작은(flat) 최소점에 수렴하는 새로운 근사 2차 최적화 방법을 설계하였다. 그러나 곡률을 단순하게 줄이려는 과정에서 근사된 헤시안이 과도하게 억제되어 학습이 불안정해지는 문제가 발생한다. 이를 해결하기 위해, 본 연구에서는 곡률을 최소화하는 과정에서도 헤시안을 안정적으로 근사할 수 있는 기법을 고안하였으며, 이를 바탕으로 SASSHA (Sharpness-aware Adaptive Second-order Optimization with Stable Hessian Approximation) 라는 새로운 알고리즘을 제안한다.
SASSHA는 기존의 2차 최적화 기법들보다 더 평평한 최소점 (flat minima)에 안정적으로 수렴함으로써 일반화 성능이 향상될 뿐 아니라, 최적화 경로 역시 곡률 변화가 적은 평탄한 영역을 따라가도록 유도된다. 이로 인해 과거에 계산한 헤시안 정보를 재사용하더라도 성능 저하 없이 학습을 지속할 수 있어, 헤시안 계산 횟수를 줄여 계산 효율성을 크게 향상시킬 수 있다.
SASSHA는 이미지 분류, 자연어 처리 등 다양한 표준 딥러닝 과제에서 기존의 1차 및 2차 최적화 기법들을 모두 능가하였으며, 특히 레이블 노이즈(label noise)가 존재하는 환경에서도 기존의 최고 성능 기법인 SAM보다 더 뛰어난 견고함(robustness)을 보였다.
[연구의 의미]
딥러닝 분야에서 모델의 규모는 계속해서 커지고 있지만, 이론적으로 더 빠른 수렴 속도를 제공하는 2차 최적화 방법은 실제로는 널리 사용되지 않고 있다. 그 주요 원인은 크게 두 가지로, 첫째는 높은 계산 및 메모리 비용, 둘째는 낮은 일반화 성능이다.
본 연구에서는 근사 2차 최적화 기법이 곡률이 작은 최소점으로 안정적으로 수렴하도록 유도하는 새로운 방법론을 제시하였다. 이를 통해 해당 기법의 일반화 성능을 향상시켰을 뿐 아니라, 동시에 그 과정에서 발생하는 부가적 이점을 활용하여 계산 효율성 또한 개선하였다.
그 결과, 기존에는 이론적인 가능성에 머물렀던 2차 최적화의 빠른 수렴 속도라는 잠재력을 실용적으로 실현할 수 있는 방법론을 제시하였다. 이 방법론은 다양한 학습 분야에서 앞으로 2차 기법의 실질적 활용 가능성을 더욱 확장시킬 중요한 기반이 될 것으로 기대된다.
[연구결과의 진행 상태 및 향후 계획]
본 연구는 인공지능 분야 최우수 국제 학술대회인 국제머신러닝학회(International Conference on Machine Learning) ICML 2025 에 논문으로 채택되어, 포스터 세션을 통해 발표될 예정이다.
향후 연구에서는 SASSHA의 가치를 보다 정밀하게 입증하기 위해 다음과 같은 다양한 방향으로 연구를 확장하고자 한다. 예를 들어, 초대규모 모델과 데이터에 대한 실험 확장, 다양한 아키텍처에의 적용 가능성 검증, 그리고 수렴 속도(convergence rate), 일반화 경계(generalization bound), 내재된 편향(implicit bias)과 같은 이론적 특성의 분석이 포함된다.
우리는 이러한 후속 연구를 SASSHA의 이론적·실용적 기여를 심화시킬 수 있는 의미 있는 기회로 보고 있으며, 지속적인 탐구를 이어갈 계획이다.
[성과와 관련된 실적]
Dahun Shin, Dongyeop Lee, Jinseok Chung, and Namhoon Lee. “SASSHA: Sharpness-aware Adaptive Second-order Optimization with Stable Hessian Approximation”, International Conference on Machine Learning (ICML), 2025.
[성과와 관련된 이미지]