연구
최신연구
View
| [박은혁 교수] SEAL: Scaling to Emphasize Attention for Long-Context Retrieval | ||
|---|---|---|
| 작성자 시스템 | 작성일 25/07/10 (00:00) | 조회수 900 |
[연구의 필요성]
대규모 언어 모델 (Large Language Models, LLM)을 아주 긴 문서 전체의 이해 등 장문맥 (long-context)에 활용하려는 요구가 점차 늘어나고 있습니다. 이에 따라 확장된 입력 길이를 받을 수 있는 LLM 혹은 각종 확장 기법들이 등장하고 있지만, 여전히 입력 길이가 길어질수록 점차 검색 능력이 떨어진다는 문제가 있습니다.
한편 이러한 장문맥 이해를 가능케 하는 핵심 요소인 멀티 헤드 어텐션 (Multi-head Attention, MHA) 구조에서 어텐션 헤드별로 다른, 다양한 역할을 가지고 있음이 알려져있습니다. 본 연구의 결과물을 활용하면 장문맥 검색 (long-context retrieval)에 관여하는 헤드들을 찾을 뿐만 아니라 해당 헤드들의 영향력을 조절하여 긴 입력에 대한 검색 성능 저하 문제를 해결할 수 있습니다.
[포스텍이 가진 고유의 기술]
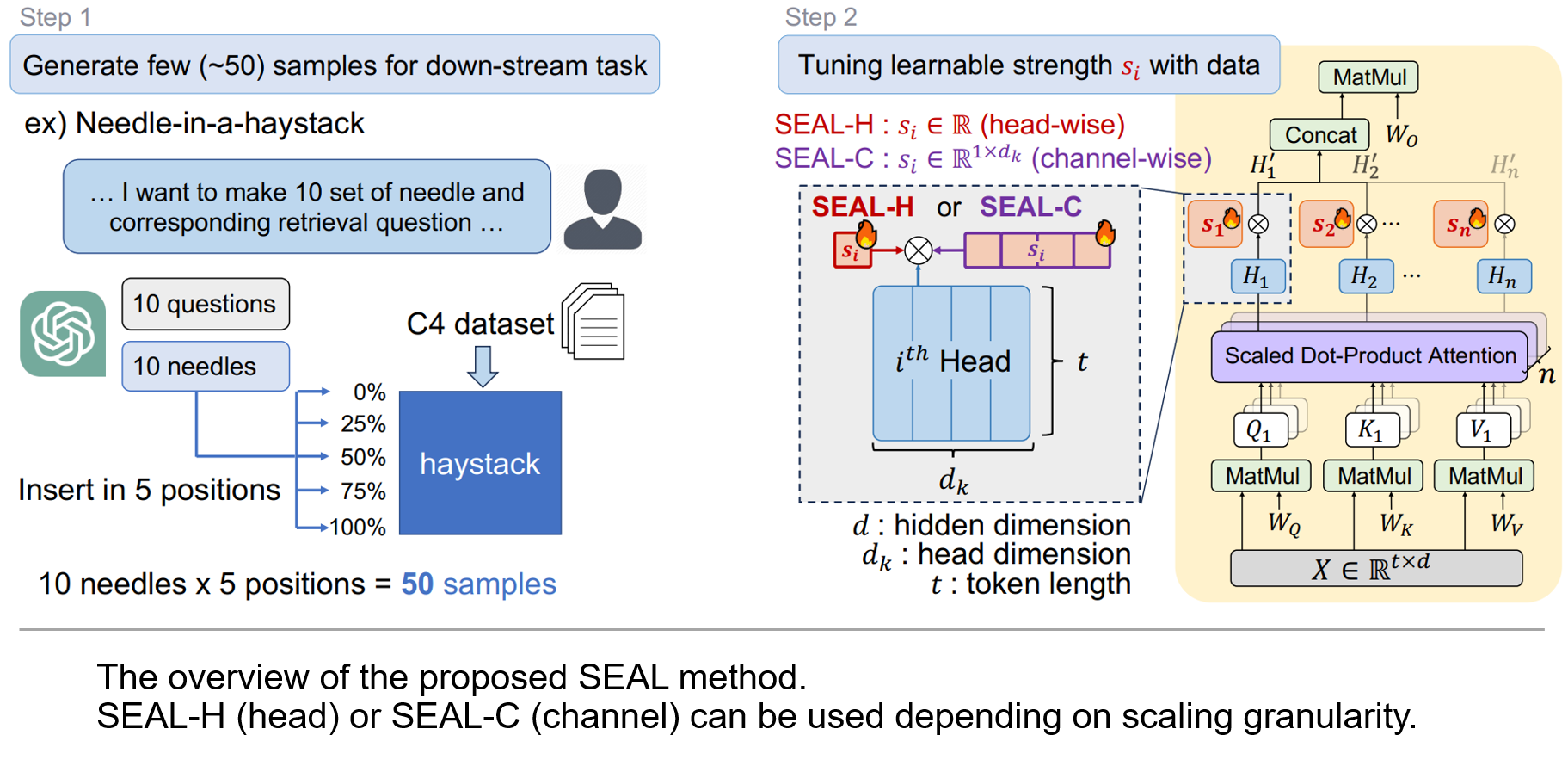
본 연구에서는 분석 실험을 통해 멀티 헤드 어텐션 구조에서 어떤 특정 헤드를 제거함에 따라 20% 정도의 검색 정확도 향상에서 30% 정도의 하락까지 관찰하였습니다. 이를 통해 실제로 특정 헤드들이 장문맥 검색에 중요한 역할을 한다는 것을 확인했고, 나아가 헤드 내부의 채널별 제거 실험에서 큰 정확도 편차를 확인하여 채널 단위의 어텐션 조절 또한 중요함을 확인하였습니다. 해당 분석들을 바탕으로 어텐션 헤드별 (head-wise) 혹은 더 세밀하게 채널별 (channel-wise) 세기를 적절히 조절하는 어텐션 스케일링 방법인 SEAL을 제안합니다. SEAL은 단 50개 정도의 합성 훈련 데이터셋을 만든 뒤, 그 데이터셋으로 scale을 미세조정 (fine-tuning) 하는 방법으로 어텐션 성분들의 세기를 장문맥 검색에 맞게 적절히 조절합니다. 저희의 방법은 추론 시 추가적인 연산 오버헤드 없이, 1시간 이내의 미세조정 만으로도 다양한 검색 테스크의 성능하락을 크게 복구시켰습니다.
[연구의 의미]
본 연구에서는 어텐션 출력에 적절한 스케일링 만으로 장문 검색 성능을 크게 향상시키는 새로운 미세 조정 방법을 제안하였습니다. 그 과정에서 대조군 미세조정 방법들에 비해 아주 적은 학습 파라미터로 비슷한 성능향상을 달성했고, 이를 통해 어텐션 요소들 (헤드, 채널)이 이런 검색 능력에 핵심 요소임을 보였습니다. 뿐만 아니라 학습 없이 문맥창을 확장하는 (training-free context length extension) 방법들에 SEAL을 같이 사용하여 전체적인 조정 비용도 적게 유지하며 확장된 입력 길이에서의 성능 하락도 해결하는 방법을 추가로 제안하였습니다. 이와 같이 작은 조정 비용으로 유효한 문맥창을 확장하는 기법과 다양한 분석을 제시함으로써, 장문맥 LLM (long-context LLM)의 활용 및 발전에 기여했다는 점에서 의의가 있습니다.
[연구결과의 진행 상태 및 향후 계획]
본 연구는 자연어 처리 분야 최우수 학술대회 중 하나인 The 63rd Annual Meeting of the Association for Computational Linguistics (ACL 2025) 에 채택되어 포스터 세션에서 발표될 예정입니다. 향후 정보검색의 품질 하락 문제 뿐만 아니라 긴 입력에 대한 추론 속도 개선 및 메모리 비용을 낮추기 위한 최적화 연구 또한 계획 중입니다.
[성과와 관련된 실적]
Changhun Lee, Minsang Seok, Jun-gyu Jin, Younghyun Cho, Eunhyeok Park, “SEAL: Scaling to Emphasize Attention for Long-Context Retrieval”, ACL 2025 Main