연구
최신연구
View
| [한욱신 교수] TRIAL: Token Relations and Importance Aware Late-interaction for Accurate Text Retrieval | ||
|---|---|---|
| 작성자 한욱신 | 작성일 25/09/03 (00:00) | 조회수 876 |
[연구의 필요성]
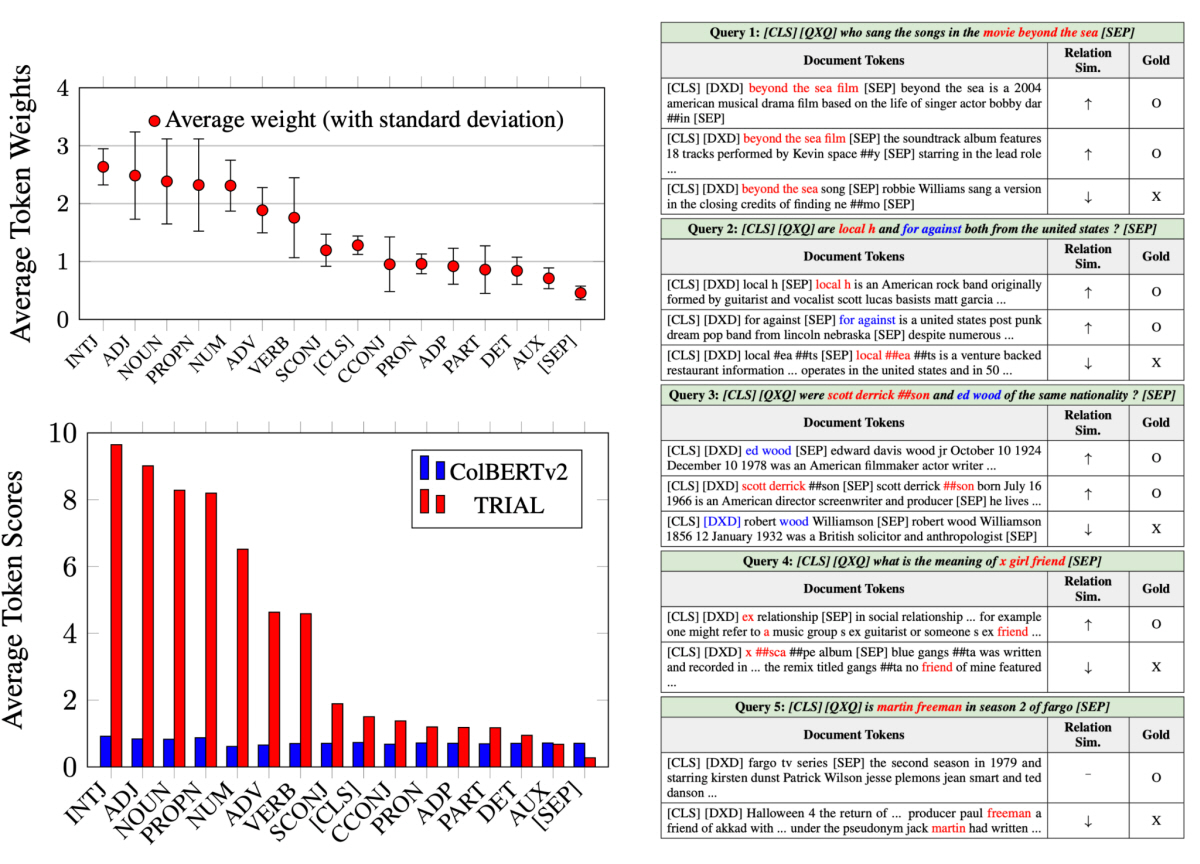
Late-interaction 기반 다중 벡터 검색 시스템은 대규모 문서 검색에서 속도와 정확도를 크게 향상시켰으나, 토큰 레벨 유사도 점수를 단순 합산하는 방식으로 인해 두 가지 주요 한계가 발생한다. 첫째, 의미 단위(단어·구절)가 토큰화로 분리되어 독립적으로 매칭되면, 문맥상 무관한 문서가 높은 점수를 받을 수 있다(예: “Scott Derrickson”이 “scott”, “derrick”, “##son”으로 나뉘어 불필요한 매칭 발생). 둘째, 관사·전치사 같은 저내용 단어의 영향력을 무시하지 못해 관련성 추정이 부정확해진다. 기존 방법들(ColBERT, COIL 등)은 이러한 토큰 분리와 중요도 문제를 고려하지 않아, 특히 다중 토큰 엔티티나 기능어 중심 쿼리에서 검색 정확도가 제한된다. 이는 검색 엔진·질문응답 시스템 등에서 신뢰할 수 있는 결과를 제공하는 데 장애가 되며, 대형 언어 모델 기반 검색 증강 생성(RAG)에서도 관련 컨텍스트 공급의 질을 떨어뜨린다.
[포스텍이 가진 고유의 기술]
- 본 연구진은 TRIAL(Token Relations and Importance Aware Late-interaction)이라는 새로운 Late-interaction 방식을 제안한다. 핵심은 토큰 관계와 중요도를 명시적으로 모델링하여 관련성 점수를 정밀하게 계산하는 것이다.
(1) 토큰 관계 점수: 쿼리·문서 토큰 간 관계를 MLP 기반 Rel 함수로 인코딩하고, 도트 프로덕트로 유사도를 측정한다. 이를 통해 다중 토큰 엔티티(예: 명사구)를 일관된 의미 단위로 취급하며, 부분 매칭 노이즈를 줄인다(예: “Ed Wood” vs. “Robert Wood” 구분).
(2) 토큰 중요도 가중치: 쿼리 토큰별 Gate 함수(Mish·ReLU 활성화 기반 2층 네트워크)를 통해 중요도를 예측하고, 관련성 점수에 가중한다. 이는 내용 중심 토큰(명사·형용사)을 강조하고 기능어(관사·보조동사)를 억제한다.
점수 함수는 기존 MaxSim에 관계 점수와 중요도 가중치를 통합하며, 훈련 시 KL 발산·교차 엔트로피 손실과 L1 정규화로 최적화한다. 검색 단계에서는 PLAID 알고리즘을 수정해 쿼리 중요도를 유사도 계산 과정에 반영한다. 요약하면, TRIAL은 ‘토큰 관계 인코딩 + 중요도 가중 메커니즘’으로 기존 Late interaction의 한계를 극복하며 정확성과 효율성을 동시에 달성한다.
[연구의 의미]
TRIAL은 MSMARCO(nDCG@10 46.3), BEIR(평균 nDCG@10 51.09), LoTTE Search(평균 Success@5 72.15) 벤치마크에서 SOTA를 달성하며, 희소·밀집 검색 방법들을 모두 능가했다. 특히 BEIR에서 SPLADE++ 대비 평균 0.39%p, ColBERTv2 대비 1.14%p 향상됐으며, LoTTE Search에서 ColBERTv2 대비 0.24%p 상승을 보였다. 이는 토큰 관계가 다중 토큰 구절의 의미적 의존성을 포착하고, 중요도 가중이 핵심 용어를 우선시한 효과로 해석된다. Ablation study에서 관계·중요도 제거 시 BEIR 평균이 각각 1.24%p·1.21%p 하락해 각 구성의 기여를 확인했다. 질적 분석에서도 부분 매칭 문서를 낮추고 금문서 순위를 높이는 효과가 뚜렷했다. 효율성 측면에서 쿼리 처리 시간은 ColBERTv2 대비 15.4% 증가(603ms vs. 523ms)에 그치며, 최대 200토큰 입력에서도 1200ms 이내 처리되어 대규모 검색 실용성을 유지한다. POS 태그 분석 결과, 내용 토큰(NOUN·ADJ) 점수가 0.8에서 최대 9.74로 증폭돼 정밀 관련성 추정이 가능해짐을 입증했다.
[연구결과의 진행 상태 및 향후 계획]
현재 TRIAL은 MSMARCO 훈련 기반으로 세 벤치마크에서 평가를 완료했으며, 어블레이션·질적 분석을 통해 효과성을 검증했다. 코드와 데이터는 공개되어 재현성을 갖췄다. 그러나 관계 모델링으로 인한 계산 오버헤드, 영어 중심 평가, LoTTE Forum 같은 장문·비공식 쿼리에서의 상대적 약점 등이 한계로 확인됐다.
향후 계획으로는 다국어 확장(형태소 풍부 언어 지원)과 계산 최적화(병렬 GPU 활용 강화)를 통해 효율성을 높이고, 도메인 이동 문제를 해결하기 위해 포럼·장문 쿼리 적응 훈련이 있다.
[성과와 관련된 실적]
Hyukkyu Kang, Injung Kim, Wook-Shin Han. “TRIAL: Token Relations and Importance Aware Late-interaction for Accurate Text Retrieval,” EMNLP 2025 Main Conference.
[성과와 관련된 이미지]