연구
최신연구
View
| [이남훈 교수] The Unseen Frontier: Pushing the Limits of LLM Sparsity with Surrogate-Free ADMM | ||
|---|---|---|
| 작성자 시스템 | 작성일 25/12/16 (14:18) | 조회수 1205 |
[연구의 필요성]
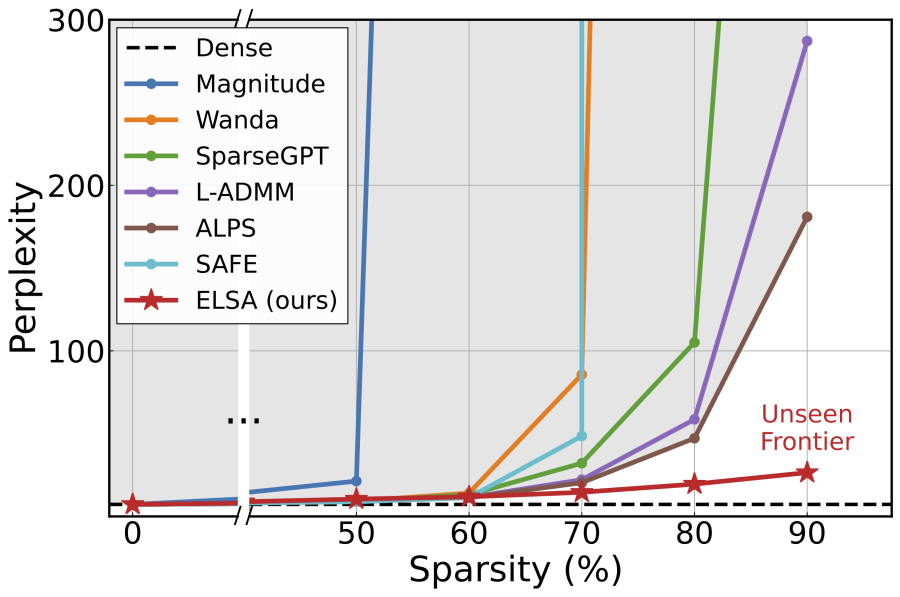
거대 언어 모델의 활용 급증으로 모델 구동 비용이 증가함에 따라, 연산 및 메모리 절감을 위한 모델 압축 기법의 중요성이 커지고 있다. 특히 파라미터를 제거하는 가지치기(pruning)는 핵심적인 방법론으로, 연산량과 메모리 압축률을 확보할 수 있다. 그런데 기존 연구는 자원 효율성이 크게 증가하는 높은 압축률 구간(예: 70% 이상)에서 심각한 성능 저하를 겪는 문제가 있어, 고압축률에서도 성능을 확보해야하는 문제가 남아있다.
[포스텍이 가진 고유의 기술]
본 연구는 제약 최적화 기법을 토대로, 원목적 함수 기반 극한 희박도의 언어모델 압축 기법을 제안한다. 기존 연구의 한계점이 희소화 과정에 자원 제약으로 인한 대리목적 함수 기반의 설계에 존재할 수 있는 가능성을 주목하여, 대리 목적 함수가 아닌 원목적 함수 기반의 거대 언어모델 희소화를 목적으로한 제약 최적화 문제를 설정하고, 이를 교차방향승수법(ADMM)을 적용하여 ELSA (Extreme LLM Sparsity with surrogate-free ADMM) 알고리즘을 설계하였다. 특히, 이 과정에서 사영을 통해 진행되는 희소화 과정의 해가 원목적함수의 해와 멀어질 수 있다는 점에 착안하여, 사영 과정에 목적함수의 곡률 정보를 주입하였고, 더욱 큰 모델의 희소화를 지원하기 위해 알고리즘에 사용되는 변수를 양자화할 수 있는 ELSA-L을 추가로 제안하였다.
[연구의 의미]
본 연구는 기존 거대언어모델 희박화 연구에서 도달하지 못했던 고희박도 (90%) 영역 달성을 위해 원목적함수의 중요성을 규명하고 이를 통해 실제로 도달할 수 있음을 시연하였다. 이를 위해 제약 최적화 기반의 원목적 함수 기반 희박화 기법을 설계하고 원목적함수에 더욱 적합한 설계로 고도화 및 수렴성 등 이론적으로 분석하였다. 다양한 거대 언어모델 종류 및 크기에서 기존 방법보다 매우 뛰어난 고희박도 성능을 확보할 수 있음을 보였고, 특히 가장 많이 사용되는 LLaMA-2-7B 모델의 90%희박도에서 기존 기법 대비 x7.8배 낮은 perplexity를 기록하였다. 이러한 성능에서 원래의 모델 대비 x2.5배의 추론 속도 향상 및 x4.6배의 메모리 압축률이 가능함을 보였고, 이는 대규모 언어 모델이 많이 활용되는 상황에서, 희박화를 통해 구동 비용을 획기적으로 줄일 수 있는 효과적이고 이론적인 새로운 방안을 제시하였다는 점에서 학술적·실용적 의의가 크다.
[연구결과의 진행 상태 및 향후 계획]
본 연구는 한국인공지능학회 추계학술대회 / Joint conference on Korean Artificial Intelligence Association (JKAIA 2025)에서 한국남동발전 최우수 논문상을 수상하였다. 향후 연구에서는 이를 초대규모 모델에 확장 적용 및 초고희박도에서의 성능 확보를 할 수 있도록 알고리즘을 개선하는 것을 목표로 한다.
[성과와 관련된 실적]
2025 한국인공지능학회 추계학술대회 한국남동발전 최우수논문상 수상 / 이관희 석사과정(인공지능대학원), 장현도 석사과정(인공지능대학원), 이동엽 석사과정(인공지능대학원), 이남훈 교수(컴퓨터공학과)
[성과와 관련된 이미지]