연구
최신연구
View
| [전명재 교수] REP: Resource-Efficient Prompting for Rehearsal-Free Continual Learning | ||
|---|---|---|
| 작성자 시스템 | 작성일 26/02/05 (00:00) | 조회수 826 |
[연구의 필요성]
연속 학습(continual learning, CL)은 모델이 순차적인 태스크를 학습하며 지식을 축적할 수 있게 하나, 새로운 데이터를 학습할 때 기존 지식을 손실하는 ‘치명적 망각(catastrophic forgetting)’ 현상이 여전한 난제로 남아있다. 특히 온디바이스(on-device) 환경은 보안을 위한 로컬 학습이 필수적임에도 불구하고, 1~8GB 수준의 제한된 메모리와 전력 소모 제약으로 인해 실질적인 도입에 큰 어려움이 있다. 기존의 프롬프트 기반 학습은 파라미터 효율성을 높여 망각을 억제하는 효과가 있으나, 학습 과정의 연산 부하와 메모리 점유율은 여전히 엣지 디바이스의 하드웨어 한계를 위협하며 시스템 충돌이나 저장 장치 수명 단축을 초래한다. 이에 따라 모델의 정확도는 유지하면서도 연산 자원을 획기적으로 절감하여, 실질적인 온디바이스 배포를 가능케 하는 '자원 효율적(resource-efficient) 연속 학습 기법'의 필요성이 대두되었다.
[포스텍이 가진 고유의 기술]
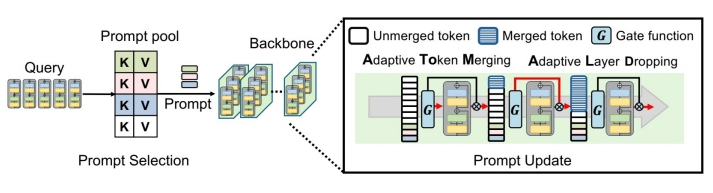
본 연구팀은 비전 트랜스포머(ViT)를 기반으로 자원 효율성을 극대화한 REP(Resource-Efficient Prompting) 프레임워크를 제안하였다. 제안한 방법은 학습 전 과정을 '프롬프트 선택'과 '프롬프트 업데이트' 단계로 최적화하는 이원화 전략을 채택하였다. 먼저 프롬프트 선택 단계에서는 무거운 메인 모델 대신 초경량 대리 모델(surrogate model)과 랜덤 투영(random projection)을 활용한 고속 추출 기법을 도입하였다. 프롬프트 업데이트 단계에서는 입력 데이터 특성에 따라 연산을 줄이는 적응형 토큰 병합(AToM)과, 태스크 민감도가 낮은 레이어를 선택적으로 연산에서 제외하는 적응형 레이어 드롭(ALD) 기술을 도입하였다. 이러한 설계를 바탕으로 연속 학습 환경에서 연산을 비균일(non-uniform)하게 생략함으로써, 정확도 손실을 최소화하면서도 높은 자원 효율성을 확보하였다.
[연구의 의미]
본 연구는 온디바이스 연속 학습의 병목 구간인 자원 효율성 문제를 정교한 비용-정확도 트레이드오프 분석을 통해 해결했다는 점에서 중요한 의의를 갖는다. 특히 제안된 REP 프레임워크는 7가지 최신 기법에 즉시 적용 가능한 높은 범용성을 갖추었으며, 프롬프트를 사용하지 않는 연속학습 기법에서도 학습 시간 최대 51%, 메모리 사용량 최대 41% 절감이라는 탁월한 성능을 입증하였다. 이는 향후 로보틱스, 스마트 모빌리티 및 개인화 엣지 컴퓨팅 등 실시간성과 효율성이 동시에 요구되는 차세대 산업 분야에서 안정적인 AI 학습을 수행할 수 있는 실질적인 기술적 토대가 될 것으로 기대된다.
[연구결과의 진행 상태 및 향후 계획]
본 연구는 기계학습 분야 최우수 국제학술대회인 NeurIPS 2025에서 포스터로 발표되었다. 향후 멀티모달 분야로의 확장 연구를 진행 중이다.
[성과와 관련된 실적]
Sungho Jeon, Xinyue Ma, Kwang In Kim, Myeongjae Jeon, “REP: Resource-Efficient Prompting for Rehearsal-Free Continual Learning”, Neural Information Processing Systems (NeurIPS), 2025.
[성과와 관련된 이미지]