연구
최신연구
View
| [전명재 교수] OrbitFlow: SLO-Aware Long-Context LLM Serving with Fine-Grained KV Cache Reconfiguration | ||
|---|---|---|
| 작성자 시스템 | 작성일 26/02/05 (00:00) | 조회수 1016 |
[연구의 필요성]
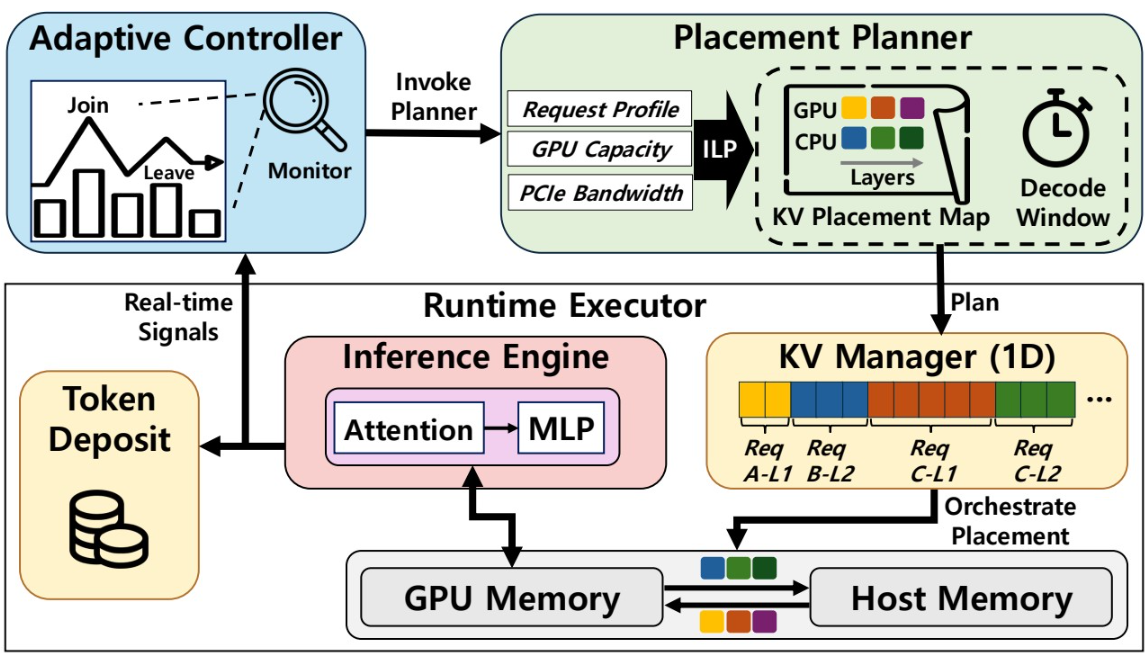
최근 GPT-4나 Claude와 같은 대규모 언어 모델(LLM)은 수십만에서 수백만 토큰에 이르는 긴 문맥(Long-context)을 처리하는 능력이 핵심 경쟁력이 되었다. 이러한 긴 문맥을 실시간으로 처리하기 위해서는 방대한 양의 'KV 캐시(Key-Value Cache)'를 GPU 메모리에 저장해야 하는데, 문맥이 길어질수록 메모리 요구량이 기하급수적으로 증가하여 GPU 용량을 초과하는 문제가 발생한다. 이를 해결하기 위해 메모리 부족 시 KV 캐시 일부를 CPU로 이동시키는 '오프로딩(Offloading)' 기법이 사용되지만, 기존의 정적이고 획일적인 오프로딩 방식은 실시간으로 급변하는 메모리 수요와 요청(Request)마다 다른 처리 단계를 유연하게 반영하지 못한다. 이로 인해 CPU와 GPU 간의 과도한 데이터 전송이 발생하여 지연 시간(Latency)이 급증하고, 결과적으로 사용자에게 약속된 응답 속도 목표(Service-Level Objectives, SLO)를 빈번하게 위반하는 한계가 있었다. 따라서 제한된 GPU 자원 내에서 긴 문맥을 처리하면서도, 사용자 경험을 저해하지 않도록 지연 시간을 엄격히 준수할 수 있는 새로운 서빙 시스템이 필요하다.
[포스텍이 가진 고유의 기술]
본 연구팀은 긴 문맥 LLM 서빙을 위한 세밀하고 적응적인 KV 캐시 관리 시스템인 OrbitFlow를 개발하였다. OrbitFlow의 핵심은 기존의 레이어(Layer) 단위가 아닌, 각 사용자 요청(Request) 단위로 KV 캐시의 위치(GPU 또는 CPU)를 결정하는 '세밀한(Fine-grained) 오프로딩 전략'에 있다. 연구팀은 경량화된 정수 선형 계획법(ILP) 솔버를 도입하여, 현재 처리 중인 모든 요청의 상태와 남은 GPU 메모리, 통신 대역폭을 고려해 최적의 캐시 배치 계획을 실시간으로 수립한다. 만약 추론 과정에서 계획이 더 이상 유효하지 않게 되면 즉시 재설정을 수행하여 변화에 대응한다. 또한, 시스템 과부하 시에도 전체적인 SLO 준수를 위해 '토큰 예치(Token Deposit)'와 '일시 정지-재개(Pause-Resume)' 메커니즘을 고안했다. 이는 생성된 토큰을 즉시 전송하지 않고 버퍼에 담아두었다가 일정한 속도로 내보냄으로써 사용자가 지연을 느끼지 못하게 하고, 그 사이 메모리를 많이 차지하는 작업을 일시 정지시켜 시스템의 안정성을 확보하는 독창적인 기술이다.
[연구의 의미]
본 연구는 LLM 서비스의 핵심 난제인 '긴 문맥 처리'와 '응답 속도 보장'이라는 두 마리 토끼를 동시에 잡은 획기적인 프레임워크를 제시했다는 점에서 큰 의의가 있다. OrbitFlow는 기존의 고정된 오프로딩 방식이 갖는 비효율성을 타파하고, 동적인 런타임 환경에 맞춰 GPU 자원 활용을 극대화하였다. 실험 결과, OrbitFlow는 기존 최고 성능의 베이스라인 모델들(FlexGen, DeepSpeed 등) 대비 토큰당 지연 시간(TPOT)과 토큰 간 지연 시간(TBT)의 SLO 달성률을 각각 최대 66%, 48% 향상시켰다. 또한 꼬리 지연 시간(95 Percentile Latency)을 38% 감소시키면서도 처리량(Throughput)은 최대 3.3배 높이는 압도적인 성능을 입증했다. 이는 고가의 GPU 증설 없이도 긴 문맥을 다루는 챗봇, 문서 분석, 실시간 번역 등의 고성능 AI 서비스를 안정적으로 제공할 수 있는 기반 기술이 될 것으로 기대된다.
[연구결과의 진행 상태 및 향후 계획]
본 연구 성과는 데이터베이스 및 시스템 분야의 최우수 국제학술대회인 VLDB(International Conference on Very Large Data Bases) 2026에 게재 승인되었다. 향후에는 더욱 거대한 모델과 복잡한 워크플로우를 가진 다중 에이전트 환경에서도 안정적인 서빙이 가능하도록 고도화할 계획이다.
[성과와 관련된 실적]
Xinyue Ma, Heelim Hong, Taegeon Um, Jongseop Lee, Seoyeong Choy, Woo-Yeon Lee, and Myeongjae Jeon, "OrbitFlow: SLO-Aware Long-Context LLM Serving with Fine-Grained KV Cache Reconfiguration", Proceedings of the VLDB Endowment (PVLDB), Vol. 19, No. 5, 2026.
[[연구의 필요성]
최근 GPT-4나 Claude와 같은 대규모 언어 모델(LLM)은 수십만에서 수백만 토큰에 이르는 긴 문맥(Long-context)을 처리하는 능력이 핵심 경쟁력이 되었다. 이러한 긴 문맥을 실시간으로 처리하기 위해서는 방대한 양의 'KV 캐시(Key-Value Cache)'를 GPU 메모리에 저장해야 하는데, 문맥이 길어질수록 메모리 요구량이 기하급수적으로 증가하여 GPU 용량을 초과하는 문제가 발생한다. 이를 해결하기 위해 메모리 부족 시 KV 캐시 일부를 CPU로 이동시키는 '오프로딩(Offloading)' 기법이 사용되지만, 기존의 정적이고 획일적인 오프로딩 방식은 실시간으로 급변하는 메모리 수요와 요청(Request)마다 다른 처리 단계를 유연하게 반영하지 못한다. 이로 인해 CPU와 GPU 간의 과도한 데이터 전송이 발생하여 지연 시간(Latency)이 급증하고, 결과적으로 사용자에게 약속된 응답 속도 목표(Service-Level Objectives, SLO)를 빈번하게 위반하는 한계가 있었다. 따라서 제한된 GPU 자원 내에서 긴 문맥을 처리하면서도, 사용자 경험을 저해하지 않도록 지연 시간을 엄격히 준수할 수 있는 새로운 서빙 시스템이 필요하다.
[포스텍이 가진 고유의 기술]
본 연구팀은 긴 문맥 LLM 서빙을 위한 세밀하고 적응적인 KV 캐시 관리 시스템인 OrbitFlow를 개발하였다. OrbitFlow의 핵심은 기존의 레이어(Layer) 단위가 아닌, 각 사용자 요청(Request) 단위로 KV 캐시의 위치(GPU 또는 CPU)를 결정하는 '세밀한(Fine-grained) 오프로딩 전략'에 있다. 연구팀은 경량화된 정수 선형 계획법(ILP) 솔버를 도입하여, 현재 처리 중인 모든 요청의 상태와 남은 GPU 메모리, 통신 대역폭을 고려해 최적의 캐시 배치 계획을 실시간으로 수립한다. 만약 추론 과정에서 계획이 더 이상 유효하지 않게 되면 즉시 재설정을 수행하여 변화에 대응한다. 또한, 시스템 과부하 시에도 전체적인 SLO 준수를 위해 '토큰 예치(Token Deposit)'와 '일시 정지-재개(Pause-Resume)' 메커니즘을 고안했다. 이는 생성된 토큰을 즉시 전송하지 않고 버퍼에 담아두었다가 일정한 속도로 내보냄으로써 사용자가 지연을 느끼지 못하게 하고, 그 사이 메모리를 많이 차지하는 작업을 일시 정지시켜 시스템의 안정성을 확보하는 독창적인 기술이다.
[연구의 의미]
본 연구는 LLM 서비스의 핵심 난제인 '긴 문맥 처리'와 '응답 속도 보장'이라는 두 마리 토끼를 동시에 잡은 획기적인 프레임워크를 제시했다는 점에서 큰 의의가 있다. OrbitFlow는 기존의 고정된 오프로딩 방식이 갖는 비효율성을 타파하고, 동적인 런타임 환경에 맞춰 GPU 자원 활용을 극대화하였다. 실험 결과, OrbitFlow는 기존 최고 성능의 베이스라인 모델들(FlexGen, DeepSpeed 등) 대비 토큰당 지연 시간(TPOT)과 토큰 간 지연 시간(TBT)의 SLO 달성률을 각각 최대 66%, 48% 향상시켰다. 또한 꼬리 지연 시간(95 Percentile Latency)을 38% 감소시키면서도 처리량(Throughput)은 최대 3.3배 높이는 압도적인 성능을 입증했다. 이는 고가의 GPU 증설 없이도 긴 문맥을 다루는 챗봇, 문서 분석, 실시간 번역 등의 고성능 AI 서비스를 안정적으로 제공할 수 있는 기반 기술이 될 것으로 기대된다.
[연구결과의 진행 상태 및 향후 계획]
본 연구 성과는 데이터베이스 및 시스템 분야의 최우수 국제학술대회인 VLDB(International Conference on Very Large Data Bases) 2026에 게재 승인되었다. 향후에는 더욱 거대한 모델과 복잡한 워크플로우를 가진 다중 에이전트 환경에서도 안정적인 서빙이 가능하도록 고도화할 계획이다.
[성과와 관련된 실적]
Xinyue Ma, Heelim Hong, Taegeon Um, Jongseop Lee, Seoyeong Choy, Woo-Yeon Lee, and Myeongjae Jeon, "OrbitFlow: SLO-Aware Long-Context LLM Serving with Fine-Grained KV Cache Reconfiguration", Proceedings of the VLDB Endowment (PVLDB), Vol. 19, No. 5, 2026.
[성과와 관련된 이미지]