연구
최신연구
View
| [한욱신 교수] TurboLynx: Schemaless Graph Engine Strikes Back for General-Purpose Analytics | ||
|---|---|---|
| 작성자 시스템 | 작성일 26/03/23 (00:00) | 조회수 831 |
[연구의 필요성]
그래프 데이터베이스 관리 시스템(GDBMS)은 복잡한 관계를 자연스럽게 표현하고 탐색할 수 있어, 소셜 네트워크, 지식 그래프, 금융 거래망 등 다양한 분야에서 널리 활용되고 있다. 최근에는 사전에 고정된 스키마 없이도 노드와 엣지에 자유롭게 속성을 부여할 수 있는 '스키마리스(schemaless)' 프로퍼티 그래프 모델(PGM)이 주목받고 있다. Neo4j, Memgraph 등의 주요 GDBMS들이 이를 지원하며, 데이터 구조가 사전에 완전히 정해지지 않은 환경이나 빠른 변경이 잦은 환경에서 특히 유용하다.
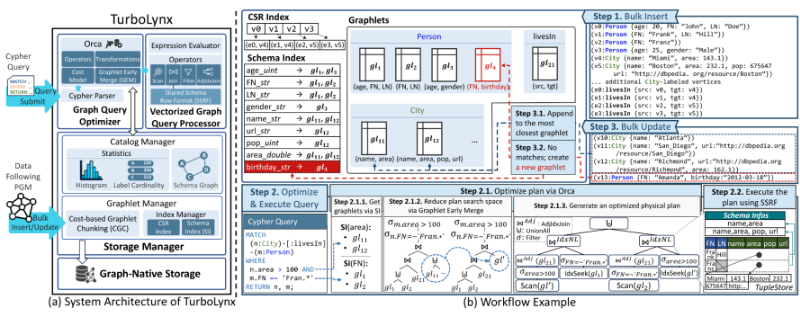
그러나 이러한 스키마리스 그래프를 지원하는 기존 GDBMS들은 그룹화, 집계, 복합 분석 질의에서 성능 저하가 크다는 한계가 있다. 이는 스키마리스 처리가 저장, 질의 처리, 질의 최적화 전 계층에서 일관되게 반영되지 않은 점이 주요한 원인이다. 특히 기존 시스템은 행 기반 저장으로 인해 튜플 단위의 스키마 해석 오버헤드가 크고, 다양한 스키마가 혼재되어 벡터화 적용이 어렵고, 자체 질의 최적화기의 성숙도도 충분하지 않아 복잡한 분석 질의에서 비효율이 발생한다.
[포스텍이 가진 고유의 기술]
포스텍 연구진은 이러한 한계를 해결하기 위해 스키마리스 그래프 데이터를 저장부터 질의 최적화까지 통합적으로 처리하는 그래프 분석 엔진 TurboLynx를 제안하고 구현하였다. 핵심 기술은 세 가지다. 첫째, CGC(Cost-based Graphlet Chunking)를 통해 유사한 속성 집합을 가진 데이터를 그래플릿 단위로 묶고 컬럼형으로 저장함으로써, 스키마 해석 비용과 null 오버헤드를 줄이면서 벡터화 효율을 높였다. 둘째, SSRF(Shared Schema Row Format)를 통해 다중 홉 탐색과 조인 과정에서 발생하는 중간 스키마 폭발과 희소 컬럼 문제를 완화하였다. 셋째, GEM(Graphlet Early Merge) 기반 최적화를 적용해 그래플릿 수 증가에 따른 실행 계획 탐색 공간의 폭증을 줄이고, 보다 효율적인 조인 순서를 찾을 수 있도록 하였다.
[연구의 의미]
본 연구의 의의는 스키마리스 그래프 처리의 병목을 저장 구조, 실행 엔진, 질의 최적화기를 분리해 보지 않고 하나의 통합된 시스템 설계 문제로 다뤘다는 점에 있다. TurboLynx는 그래프 탐색 질의와 분석 질의를 하나의 엔진에서 함께 효율적으로 처리할 수 있음을 보였고, LDBC SNB Interactive, TPC-H, DBpedia 평가에서 최신 GDBMS 대비 최대 183.9배, 주요 RDBMS 대비 최대 41.27배의 성능 향상을 달성했다. 또한 실제 지식그래프인 DBpedia에서는 스키마 다양성이 매우 큰 환경에서도 최고 경쟁 시스템 대비 18.88배 빠른 성능을 보여, 실세계 대규모 스키마리스 그래프 분석에 대한 실용성을 입증하였다.
[연구결과의 진행 상태 및 향후 계획]
본 연구 성과는 데이터베이스 분야 최고 학술대회인 VLDB 2026에 게재가 확정되었으며, 전체 소스 코드를 공개하여 학계와 산업계의 후속 연구 및 활용을 지원할 수 있도록 할 예정이다. 향후에는 병렬 환경으로의 확장과 트랜잭션 지원 기능 추가를 목표로 하고 있으며, 대규모 그래프 분석 응용을 위한 연구를 지속할 계획이다.
[성과와 관련된 실적]
Lee, T., Ha, J., Tak, B., and Han, W., “TurboLynx: Schemaless Graph Engine Strikes Back for General-Purpose Analytics,” In 52nd Int’l Conf. on Very Large Data Bases (VLDB) / Proc. the VLDB Endowment (PVLDB), Vol. 19, No. 6, pp. 1250-1263, August 2026
[성과와 관련된 이미지]