연구
최신연구
View
| [이근배 교수] Denoising Table-Text Retrieval for Open-Domain Question Answering | ||
|---|---|---|
| 작성자 시스템 | 작성일 24/03/11 (00:00) | 조회수 897 |
[연구의 필요성]
오픈 도메인 질의 응답은 일반적으로 유저의 질의와 관계 있는 문서들을 검색하고 이 문서에 기반하여 응답을 생성하는 작업으로 이뤄진다. 이는 유저의 질의에 대한 응답을 직접적으로 제공할 수 있다는 점에서 관련성 있는 검색 결과만을 제공하는 기존의 검색 엔진에 비해 효과적이다. 최근에는 검색된 문서에서 텍스트 뿐만 아니라 테이블 정보까지 동시에 고려하여 응답을 생성하는 연구(Table-Text ODQA)가 활발히 이뤄지고 있다. 그러나 기존의 연구들은 Retriever 의 학습 과정이 데이터셋에 포함된 false-positive instance로 인해 noisy했고, 테이블 단위의 정보를 처리하지 못했다. 이에 본 연구는 기존의 연구들의 문제점을 완화한 Retriever를 개발하였다.
오픈 도메인 질의 응답은 일반적으로 유저의 질의와 관계 있는 문서들을 검색하고 이 문서에 기반하여 응답을 생성하는 작업으로 이뤄진다. 이는 유저의 질의에 대한 응답을 직접적으로 제공할 수 있다는 점에서 관련성 있는 검색 결과만을 제공하는 기존의 검색 엔진에 비해 효과적이다. 최근에는 검색된 문서에서 텍스트 뿐만 아니라 테이블 정보까지 동시에 고려하여 응답을 생성하는 연구(Table-Text ODQA)가 활발히 이뤄지고 있다. 그러나 기존의 연구들은 Retriever 의 학습 과정이 데이터셋에 포함된 false-positive instance로 인해 noisy했고, 테이블 단위의 정보를 처리하지 못했다. 이에 본 연구는 기존의 연구들의 문제점을 완화한 Retriever를 개발하였다.
[포스텍이 가진 고유의 기술]
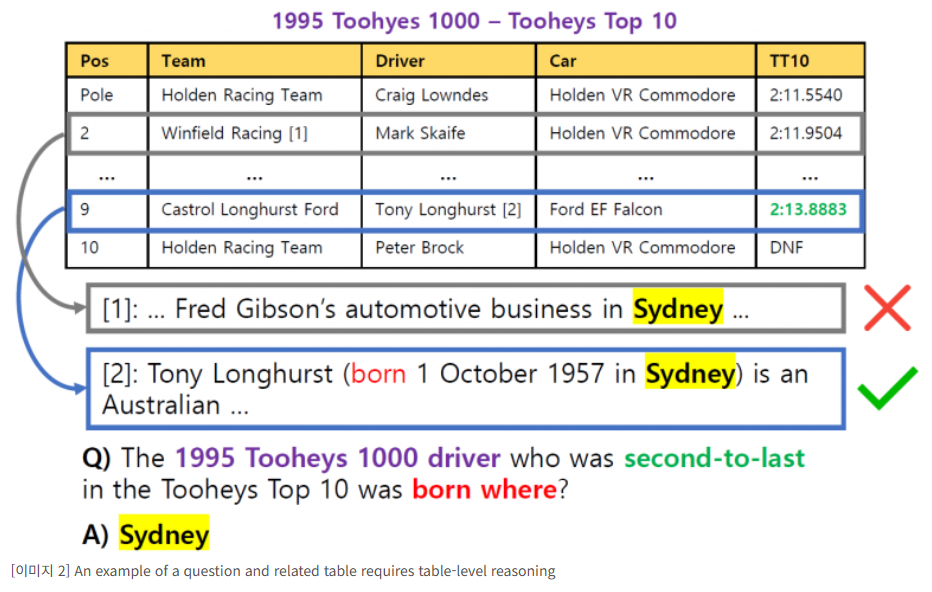
False positive detection: Retriever는 테이블의 행과 관련된 문서가 결합된 fused block을 검색 단위로 한다. 그러나 데이터셋에는 fused block 단위의 label이 되어 있지 않기에 이전 연구에서는 정답이 포함된 fused block을 positive instance로 취급하였다. 이는 정답이 테이블에서 빈번하게 등장하는 entity인 경우 false-positive training instance의 문제가 발생하게 된다. 이를 완화하기 위해 질의와 fused block간의 관련성을 수치화 하는 false-positive detection model을 훈련시켜 데이터셋을 denoising하였다.
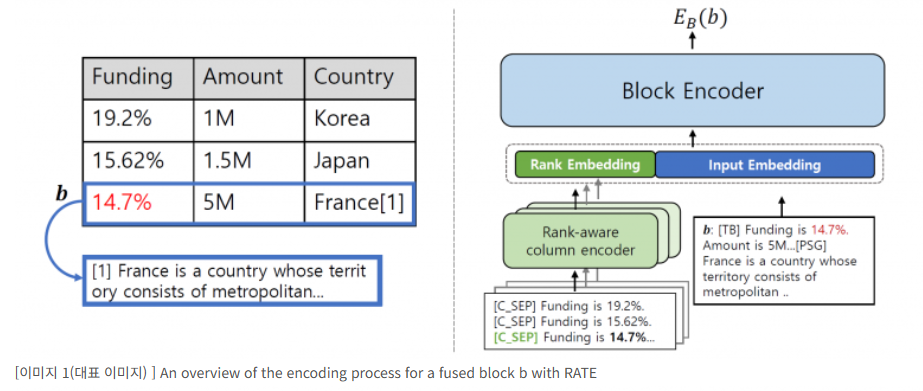
Rank-Aware Table Encoding (RATE): Fused block의 정보는 Table의 행 단위에 국한되어 있기에 질의가 테이블 단위의 비교를 요구하는 경우에는 검색기가 이를 처리할 수 없다. 이에 테이블 내에 속하는 값들의 순위 정보를 Rank-aware column encoder를 통해 ranking representation으로 변환하고 Retriever를 학습시킬 때 이러한 정보를 추가적으로 제공하였다.
False positive detection: Retriever는 테이블의 행과 관련된 문서가 결합된 fused block을 검색 단위로 한다. 그러나 데이터셋에는 fused block 단위의 label이 되어 있지 않기에 이전 연구에서는 정답이 포함된 fused block을 positive instance로 취급하였다. 이는 정답이 테이블에서 빈번하게 등장하는 entity인 경우 false-positive training instance의 문제가 발생하게 된다. 이를 완화하기 위해 질의와 fused block간의 관련성을 수치화 하는 false-positive detection model을 훈련시켜 데이터셋을 denoising하였다.
Rank-Aware Table Encoding (RATE): Fused block의 정보는 Table의 행 단위에 국한되어 있기에 질의가 테이블 단위의 비교를 요구하는 경우에는 검색기가 이를 처리할 수 없다. 이에 테이블 내에 속하는 값들의 순위 정보를 Rank-aware column encoder를 통해 ranking representation으로 변환하고 Retriever를 학습시킬 때 이러한 정보를 추가적으로 제공하였다.
[연구의 의미]
본 연구에서는 기존의 Retriever 모델들이 간과하고 있던 한계점을 지적하였으며, 이를 개선하여 fused-block 단위의 검색 성능에서 state-of-the-art (SOTA)를 달성하였다. 또한, 질의응답 성능에서도 기존 연구보다 향상된 성능을 보였다.
본 연구에서는 기존의 Retriever 모델들이 간과하고 있던 한계점을 지적하였으며, 이를 개선하여 fused-block 단위의 검색 성능에서 state-of-the-art (SOTA)를 달성하였다. 또한, 질의응답 성능에서도 기존 연구보다 향상된 성능을 보였다.
[연구결과의 진행 상태 및 향후 계획]
본 연구는 자연어처리 분야 우수 국제학술대회인 LREC-COLING 2024에 소개될 예정이다. 향후 순위 정보 뿐만 아니라 다양한 테이블 단위의 정보를 처리할 수 있는 Retriever를 개발하는 것을 목표로 하고 있다.
본 연구는 자연어처리 분야 우수 국제학술대회인 LREC-COLING 2024에 소개될 예정이다. 향후 순위 정보 뿐만 아니라 다양한 테이블 단위의 정보를 처리할 수 있는 Retriever를 개발하는 것을 목표로 하고 있다.
[성과와 관련된 실적]
Deokhyung Kang, Baikjin Jung, Yunsu Kim, and Gary Geunbae Lee, “Denoising Table—Text Retrieval for Open-Domain Question Answering”, LREC-COLING 2024 (accepted)
Deokhyung Kang, Baikjin Jung, Yunsu Kim, and Gary Geunbae Lee, “Denoising Table—Text Retrieval for Open-Domain Question Answering”, LREC-COLING 2024 (accepted)
[성과와 관련된 이미지]
- 3.8이근배교수님.png (205.3 KB)
- 3.8이근배교수님(1).png (336.8 KB)