연구
최신연구
View
| [이근배 교수] Audio-Based Linguistic Feature Extraction for Enhancing Multi-lingual and Low-Resource Text-to-Speech | ||
|---|---|---|
| 작성자 시스템 | 작성일 24/10/14 (00:00) | 조회수 244 |
[연구의 필요성]
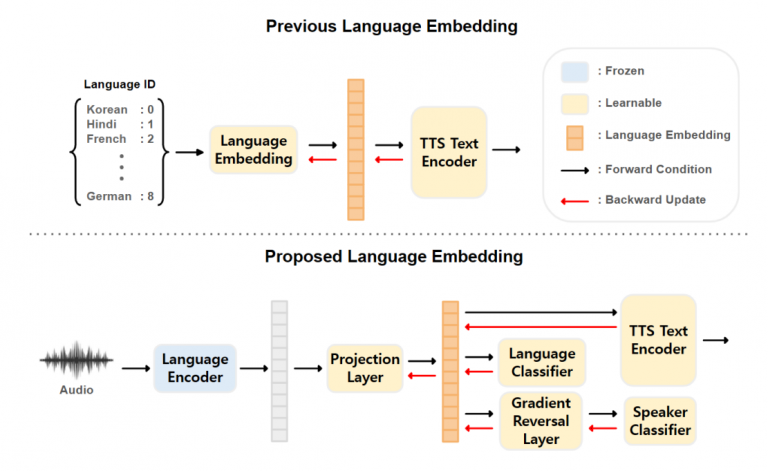
다국어 음성합성은 음성합성이라는 분야가 가지는 특성상 데이터에 큰 영향을 받을 수 밖에 없습니다. 그리고 이는 저자원 언어들에 대한 연구들로 이어지고 있습니다. 기존의 다국어 음성합성 연구들은 언어별 토큰을 사용하여 언어별 특징을 학습하기에 보지 못했던 언어에 대해서 추가적으로 학습하는 방식에 대해서 많은 부족함을 가지고 있습니다. 이를 위해서 저희는 토큰 기반 방식이 아닌 오디오로부터 바로 언어별 특징을 추출하여 학습에 활용하여 일반적인 환경에서의 다국어 음성합성뿐 아니라 저자원 환경에서도 잘 작동하는 방법론을 제시합니다.
[포스텍이 가진 고유의 기술]
언어별 특징을 추출하기 위해서 우선 speaker verification 방식으로 학습된 ECAPA-TDNN 구조로 이루어진 pretrained language encoder를 사용하였습니다. 사전학습을 진행할 때 여러가지 언어로 language classification task를 진행하여 언어별 특징을 잘 추출해낼 수 있도록 학습합니다. 그리고 저자원 환경으로의 전이학습 시에는 적은 데이터로 학습할 경우 language encoder가 편향되는 부분을 방지하기 위해서 language encoder 부분을 freezing하고 학습을 진행하였습니다. 또한 speaker adversarial training 방식을 활용해서 언어별 특징을 추출할 때, 화자에 대한 영향을 받지 않도록 하여 화자에 독립적으로 언어별로 같은 representation을 얻을 수 있도록 학습하였습니다.
[연구의 의미]
본 연구에서는 다국어 음성합성시에 언어별 토큰을 활용하지 않고 해당 언어의 특징을 추출할 수 있기에 기존에 보지 못했던 언어에 대해서도 활용할 수 있다는 장점이 있습니다. 일반적인 환경에서도 다국어의 특징을 잘 추출해내어 성능에 유의미한 효과를 가지고 왔고 저자원 환경에서도 기존보다 좋은 성능을 보이는 것을 확인하였습니다.
[연구결과의 진행 상태 및 향후 계획]
다양한 실제 저자원 언어들에 대한 적용을 시도해보고 좀더 robust하게 linguistic feature를 뽑아내기 위한 방법론을 연구할 계획입니다.
[성과와 관련된 실적]
Youngjae Kim, Yejin Jeon, Gary Geunbae Lee, “Audio-Based Linguistic Feature Extraction for Enhancing Multi-lingual and Low-Resource Text-to-Speech”, EMNLP 2024 Findings (Accepted)
[성과와 관련된 이미지]