[이근배, 김형훈 교수] Self-Correcting Code Generation Using Small Language Models
작성자 이근배, 김형훈
작성일 25/09/04 (00:00)
조회수 74
[연구의 필요성]
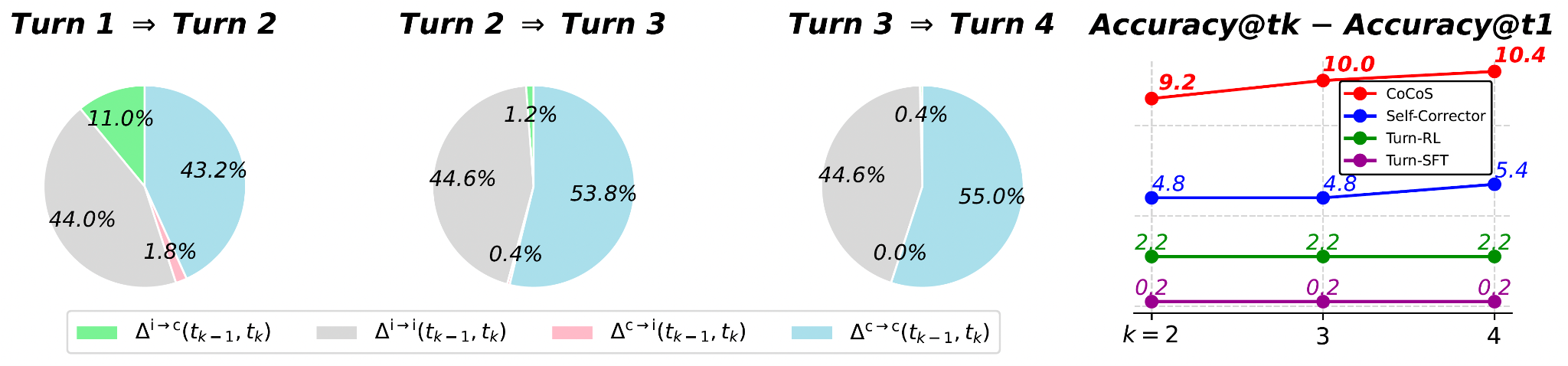
기존 연구는 대규모 언어모델 (GPT, Gemini)을 중심으로 자가 수정 능력을 탐구했으나, 소규모 모델은 생성한 코드를 스스로 점검하고 개선하는 과정에서 한계를 보여 실제 응용에 제약이 있었다. 코드 생성은 정확성과 안정성이 필수적이기에 자원 제약 환경에서도 활용 가능한 소규모 모델의 자기 수정 역량 강화가 필요하다. 그러나 지금까지 소규모 모델이 자기 성찰적 행동을 통해 성능을 향상시킬 수 있는지에 대한 연구는 부족했으며, 이에 본 연구는 누적 보상과 세밀한 보상 체계를 활용한 접근법을 제안하여 초기 응답 품질을 높이고 다중 턴 코드 수정 과정을 통해 실질적 성능 개선을 달성하고자 한다.
[포스텍이 가진 고유의 기술]
본 연구는 소규모 언어모델이 다중 턴 코드 수정에서 효과적으로 자기 수정을 수행할 수 있도록 설계된 온라인 강화학습 기반 접근법에 있다. 이를 위해 전체 수정 trajectory를 고려하는 누적 보상 함수를 도입해 초기 정답을 유지하면서 점진적 개선을 유도하고, 단순한 binary 평가를 넘어 부분적 향상까지 반영할 수 있는 (turn-wise) progressive reward function를 적용한다. 이러한 보상 설계는 소규모 모델이 외부 교사 모델에 의존하지 않고도 자기 수정 능력을 내재화하게 하며, 결과적으로 초기 응답 품질을 높이는 동시에 반복적 교정을 통해 성능을 안정적으로 향상시키는 것을 가능하게 한다.
[연구의 의미]
본 연구는 소규모 언어모델이 기존에 한계로 지적되던 자기 수정 능력을 강화할 수 있는 새로운 학습 틀을 제시했다는 데 있다. 누적 보상과 점진적 보상을 결합한 온라인 강화학습 방식을 통해, 자원 제약 환경에서도 소규모 모델이 초기 응답의 정확성을 유지하면서 반복적 교정을 통해 성능을 실질적으로 개선할 수 있음을 입증하였다.
[연구결과의 진행 상태 및 향후 계획]
본 연구는 자연어처리 분야 우수 국제학술대회인 EMNLP 2025 Findings에 소개될 예정이다. 추후에는 다양한 코드 생성 과제와 더 큰 규모의 모델에 확장 적용하여 일반화 가능성과 성능을 더욱 검증하는 것이다.
[성과와 관련된 실적]
Jeonghun Cho, Deokhyung Kang, Hyounghun Kim, Gary Geunbae Lee, Self-Correcting Code Generation Using Small Language Models, Findings of EMNLP 2025