연구
최신연구
View
| [곽수하 교수] Improving Target Presence and Plurality Recognition for Generalized Referring Image Segmentation | ||
|---|---|---|
| 작성자 시스템 | 작성일 25/12/16 (00:00) | 조회수 162 |
[연구의 필요성]
참조 영상 분할(Referring Image Segmentation, RIS)은 자연어 표현으로 기술된 영상 내 영역을 분할하는 기술로, 인간-컴퓨터 상호작용, 영상 편집, 로봇 비전 등 다양한 응용 분야에서 중요한 역할을 한다. 기존 RIS 모델들은 단일 객체만을 분할하는 것을 목표로 설계되어, 실제 환경에서 자주 발생하는 다중 객체 참조나 객체 부재 상황을 처리하지 못하는 한계를 가진다. 최근 일반화된 RIS(Generalized RIS)가 제안되어 단일 객체뿐 아니라 다중 객체 및 객체 부재 시나리오를 다루게 되었으나, 선행 연구들은 분할 특징과 객체 존재 여부 판단을 위한 특징을 동일하게 사용하여 두 작업 간 충돌이 발생하고, 객체 존재 여부 분류 성능이 크게 저하되는 문제를 보였다. 또한 데이터셋 내 객체 부재 및 다중 객체 샘플의 비중이 단일 객체 샘플에 비해 현저히 낮아(각각 9.14%, 25.53%), 모델이 이러한 시나리오를 효과적으로 학습하기 어려운 데이터 불균형 문제도 존재한다. 이에 따라 객체 존재 여부와 복수성(단일/다중)을 명시적으로 인식하고, 데이터 불균형을 해소할 수 있는 새로운 방법론의 필요성이 대두되었다.
[포스텍이 가진 고유의 기술]
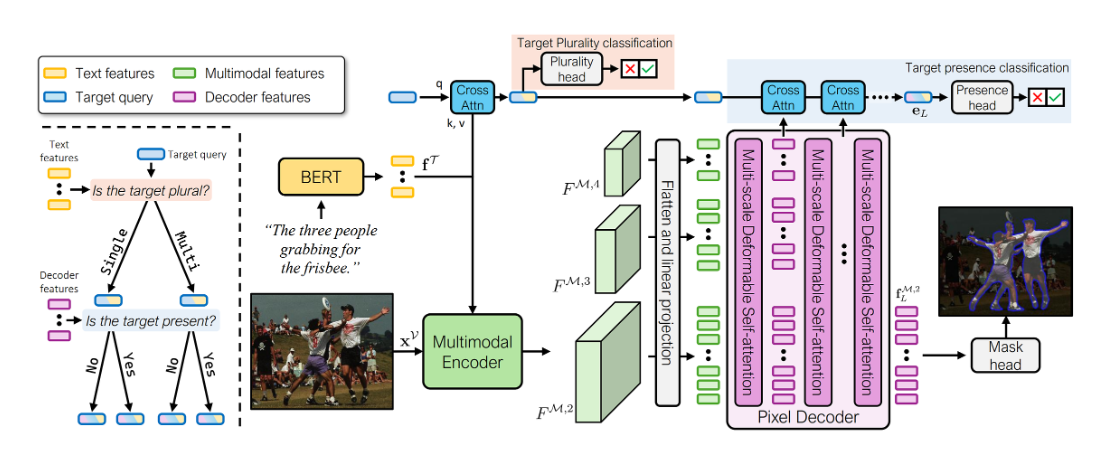
본 연구에서는 일반화된 RIS를 위한 새로운 아키텍처와 데이터 증강 전략을 제안하였다. 먼저 아키텍처 측면에서, 객체 존재 여부 분류를 위해 특별히 설계된 학습 가능한 쿼리인 '타겟 쿼리(target query)'를 도입하였다. 이 타겟 쿼리는 픽셀 디코더의 중간 특징들로부터 크로스 어텐션을 통해 정보를 집약하여 분할 특징과 독립적으로 객체 존재 여부를 판단한다. 또한 타겟 쿼리에 복수성 분류 헤드를 부착하여 텍스트 특징으로부터 직접 단일/다중 객체 여부를 학습하도록 하였다. 이를 통해 모델이 복수성 단서를 명시적으로 포착하고 복잡한 참조 시나리오에서도 정확한 마스크를 생성할 수 있도록 하였다. 데이터 증강 측면에서는 객체 부재 샘플과 다중 객체 샘플을 합성적으로 생성하는 전략을 개발하였다. 객체 부재 샘플은 배치 내 다른 영상의 텍스트 설명을 현재 영상과 쌍을 이루도록 교체하여 생성하고, 다중 객체 샘플은 최대 4개의 단일 객체 샘플을 2×2 그리드로 배열하고 텍스트를 "and"로 연결하여 생성한다. 이러한 간단하면서도 효과적인 증강 전략을 통해 데이터 불균형 문제를 완화하고 모델의 일반화 능력을 향상시켰다.
[연구의 의미]
본 연구는 일반화된 RIS에서 객체 존재 여부와 복수성 인식을 명시적으로 다루는 새로운 프레임워크를 제시했다는 점에서 중요한 의의를 갖는다. 특히 기존 방법들이 분할과 존재 여부 판단을 위해 동일한 특징을 사용하여 발생하는 성능 저하 문제를 근본적으로 해결하였으며, 타겟 쿼리라는 전용 학습 가능 임베딩을 통해 두 작업을 효과적으로 분리하였다. 또한 복수성 분류를 통해 텍스트로부터 직접 단일/다중 정보를 추출하여 마스크 생성에 활용함으로써, 모델이 다양한 참조 시나리오를 보다 정확하게 이해할 수 있도록 하였다. 제안한 데이터 증강 전략은 추가적인 인간 주석 없이도 객체 부재 및 다중 객체 샘플을 효과적으로 생성하여 데이터 불균형 문제를 해소하고, 모델 아키텍처와 무관하게 적용 가능하여 범용성이 높다. 실험 결과, gRefCOCO 데이터셋의 모든 평가 지표에서 기존 최고 성능 방법들(ReLA, LISA, GSVA 등)을 크게 상회하였으며, 특히 대규모 멀티모달 모델 기반 방법들보다 적은 파라미터로 우수한 성능을 달성하였다. 이는 향후 영상-언어 이해, 인터랙티브 영상 편집, 로봇 비전 등으로 확장될 수 있는 중요한 기술적 토대를 제공한다.
[연구결과의 진행 상태 및 향후 계획]
본 연구는 인공지능 분야 최우수 국제학술대회 AAAI 2026에 게재 승인되었다. 향후에는 더욱 복잡한 공간 관계를 다루는 다중 객체 시나리오 처리 능력 향상, 정교한 데이터 증강 기법 개발, 그리고 비디오 도메인으로의 확장 연구를 계획 중에 있다. 또한 제안한 타겟 쿼리 메커니즘을 다른 비전-언어 작업에 적용하는 연구도 진행할 예정이다.
[성과와 관련된 실적]
Namyup Kim, Jinsung Lee, Suha Kwak, "Improving Target Presence and Plurality Recognition for Generalized Referring Image Segmentation", AAAI Conference on Artificial Intelligence (AAAI), 2026.
[성과와 관련된 이미지]